Apr 23, 2026
12 min read
field note
I made 5 AI models argue with each other
What happens when models don't just answer in parallel but actually challenge each other's reasoning. Benchmarked on 50 real PRs.
A few weeks ago I pasted some auth code into Claude during a deadline crunch, got a thorough breakdown with a couple of minor flags, and was about to move on when something nagged at me. I threw the same code at GPT and got basically the same answer. On a whim I tried Gemini, and Gemini caught verify_signature: False sitting right there in the JWT config, something the other two had completely missed. The kind of bug that survives every code review, never shows up in tests, and eventually becomes a very bad day for someone.
What bothered me wasn't that two models missed it. What bothered me was that all three were equally confident, equally articulate, and I had no way of knowing which one to trust. So I started wondering what it would look like to make them actually challenge each other instead of just giving parallel opinions, and that's how verd happened.
the problem nobody's really reckoning with
We've gotten weirdly comfortable with the single-oracle pattern. You ask Claude, or GPT, or maybe Gemini, but it's always one model at a time and you just trust whatever comes back. We swapped "I Googled it" for "I asked AI" and kept the exact same single-source problem.
The research on this is grim. JudgeBench (ICLR 2025) shows LLMs pairs of responses, one correct and one subtly wrong, and asks them to pick the right one. The best model scored 64%. GPT-4o got 56%. Most fine-tuned judge models came in below 50%, which is worse than flipping a coin. TrustJudge found that in ~23% of cases, a model's pairwise preference contradicts its own numeric scores, meaning the model disagrees with itself about which answer is better. Sage (ICLR 2026) found the same consistency violations in ~25% of hard cases across GPT-5 and Gemini-2.5.
There's also a bias problem that I think gets underappreciated. The Silent Judge study showed that labeling an answer as coming from an "expert" vs a "human" vs an "LLM," even when the content is identical, causes models to systematically favor the "expert" label without ever mentioning it. The reasoning they produce sounds perfectly logical but it's driven by an irrelevant label they're not aware of. IBM catalogued 12+ distinct bias types in LLM judges. If you're using AI to review security code or decide if something is ready to ship, you're relying on a system that's right somewhere between 50-80% of the time, doesn't know when it's wrong, and won't tell you it's uncertain.
how models fail differently
After a few months of routinely asking multiple models the same question (tedious, I know), I noticed that they don't fail the same way. Claude is good at spotting nuance in business logic and API contract issues but sometimes glosses over low-level security. GPT catches performance problems and API misuse but can miss edge cases in concurrent code. Gemini is weirdly strong at regex vulnerabilities and type-safety. DeepSeek finds race conditions and timing bugs that other models treat as purely theoretical.
This makes sense when you think about it: different companies, different training data, different RLHF strategies, and none of them made the same tradeoffs. So once I saw it that way, the idea seemed obvious. Instead of asking models in parallel and hoping one catches the thing that matters, make them actually argue about it: a structured debate where models see each other's reasoning, challenge each other's claims, and have to defend their positions with evidence.
what verd actually does
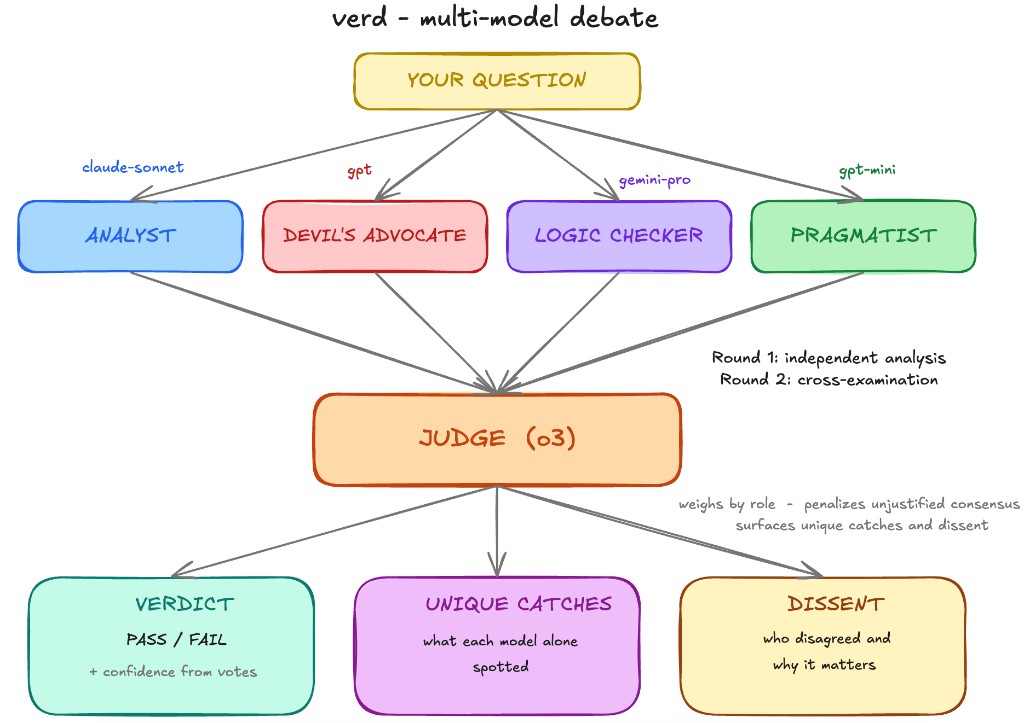
You give it a question and some context, like a code file, an architecture doc, or a config. It sends that to 4 models from different families, each assigned a specific role. They analyze independently in round 1, then see each other's responses and cross-examine in round 2. At the end, a stronger judge model reads the full debate transcript and synthesizes a verdict. In deep mode (verdh), it adds a fifth reviewer—a web-searching fact checker—and runs 3 rounds.
roles are what make it work
If you give 5 models the same prompt, they converge on basically the same answer. I tested this early and it was underwhelming: five slightly different phrasings of the same analysis, everyone agreeing with each other. The fix was giving each model a fundamentally different analytical lens.
- Analyst (
claude-sonnet-4-6): thorough, balanced assessment. The baseline, roughly equivalent to the best single-model review you'd normally get. - Devil's Advocate (
gpt-4.1): one job, find what everyone else missed. Edge cases, hidden assumptions, failure modes. The prompt literally tells them to question obvious answers. - Logic Checker (
gemini-3.1-pro): ignores the big picture and focuses purely on whether the reasoning holds up. Traces execution paths, looks for fallacies, race conditions, boundary problems. Doesn't care if everyone says PASS. - Fact Checker (
sonar-pro, deep mode only): gets web search and verifies claims against reality. Does that API actually work the way someone said? Was that library deprecated? - Pragmatist (
gpt-4.1-mini): asks the question engineers actually care about. Will this work in production, what's the ops burden, and what happens when the on-call person at 3am needs to debug it.
Each role guarantees a specific category of problem gets dedicated attention. Without roles, nobody's specifically looking for logic flaws. With roles, someone always is.
the anti-groupthink thing turned out to be critical
Here's the problem anyone building multi-agent systems will hit: models are really agreeable. They're trained to be helpful, to find common ground, to synthesize. Put 5 models in a debate and they'll converge on a comfortable consensus within one round, even when that consensus is wrong. I tried it without countermeasures first and the results were actually worse than single models in some cases: four models agree on PASS, the one that flagged something folds under peer pressure, and the debate produces a confident wrong answer. This matches what the ICLR 2025 Multi-Agent Debate study found, that naive debate frameworks often don't help and sometimes hurt.
The fix was being explicit in the cross-examination prompts. When models enter round 2, they're told:
"Do NOT change your position just because other reviewers disagree. Only change if they present NEW EVIDENCE or identify a SPECIFIC FLAW in your reasoning. Headcount is not evidence, and 4 wrong reviewers don't outweigh 1 right one."
It sounds aggressive, but it works. In the benchmarks, there were multiple cases where 3 models agreed on PASS, one held firm on FAIL with specific evidence, and the judge correctly sided with the dissenter. Without these prompts, that model would have caved.
confidence that actually means something
When a single model tells you "confidence: 0.8," that number doesn't mean much. It's not calibrated against anything; the model just generates a number that seems appropriate. verd's confidence comes from the actual vote distribution, weighted by role. A fact_checker's dissent lowers confidence more than a devil's_advocate's pushback, since pushing back is literally their job. A logic_checker finding a reasoning flaw carries more weight than an analyst expressing a general concern. The formula blends 70% vote-based math weighted by role with 30% from the judge's assessment of evidence quality, capped at 95% because verd never claims certainty. When it says 77% confidence, there's an actual meaning behind that number.
The judge (o3 in standard and heavy, o4-mini in quick mode) reads the full transcript and weighs arguments by their specificity and evidence rather than by how many models agree. It knows each model's role, trusts the fact_checker on factual claims, trusts the logic_checker on reasoning, and has to identify unique catches: what did each reviewer spot that nobody else did. That last part ends up being the most valuable output.
the architecture
| command | models | rounds | speed | cost | when to use |
|---|---|---|---|---|---|
verdl | 2 + judge | 1 | ~15-30s | ~$0.01 | quick gut check |
verd | 4 + judge | 2 | ~30-60s | ~$0.15+ | code review, architecture decisions |
verdh | 5 + judge + web | 3 | ~60-120s | ~$0.40+ | security audit, anything high-stakes |
okay but does it actually work
martian code review benchmark: 50 real PRs
Martian's Code Review Bench is an independent open-source benchmark with no stake in who wins: 50 pull requests from real projects (Cal.com, Discourse, Grafana, Keycloak, Sentry) with human-verified golden comments, bugs that experts confirmed. I ran verdh against Claude Opus 4.6 and GPT-5.4, each alone with the same prompt and no code-review-specific tuning. verd is a general-purpose debate engine, not a code review tool, and the only difference between runs was one model vs a 5-model debate.
| mode | precision | recall | F1 | avg issues |
|---|---|---|---|---|
| GPT-5.4 (alone) | 13.0% | 70.6% | 21.9% | 14.6 |
| Claude Opus 4.6 (alone) | 18.5% | 69.9% | 29.2% | 10.1 |
| verdh (5-model debate) | 29.1% | 64.0% | 40.0% | 5.9 |
verdh's F1 of 40.0% would place it around #8 on the Martian offline leaderboard, ahead of Claude Code Reviewer (39.0%) and GitHub Copilot (35.5%), and within striking distance of Devin (42.9%) and Cursor Bugbot (44.9%), all with zero domain-specific optimization. The precision story is the real headline: 57% more precise than Claude alone and 124% more precise than GPT alone, with 42% fewer issues on average. When verdh flags something, it's almost twice as likely to be a real bug.
A few standout PRs: on PR 17 (Discourse, dark theme CSS), verdh achieved 100% precision and 100% recall, finding all 3 bugs with zero false positives while Claude found them buried in 4 false positives and GPT buried them in 10. On PR 7 (Cal.com, OAuth sync), verdh hit 77% F1 and found all 5 golden bugs vs Claude's 56% and GPT's 40%. On PR 41 (Sentry, audit log pagination), verdh found all 3 bugs including Django negative slicing, auth token edge case, and datetime key type mismatch at 67% F1 vs Claude's 31%. The debate didn't win every PR, and on 2 out of 50, verdh scored lower than Claude solo because the consensus filtering removed a valid finding. Higher precision means occasionally filtering too aggressively, but across 50 PRs the math is clear.
the 10 unique catches
Across 5 bug-detection tests (TOCTOU race condition, pagination edge cases, ReDoS regex, timezone comparison, mutable default argument), verd hit 94% average confidence vs 50% for single models, and found 5.0 issues on average vs 1.2-2.8. More importantly, individual models made 10 catches that were completely unique to them, issues only one model spotted while every other missed:
| model | what only it caught |
|---|---|
| gpt-4.1-mini | Symlink/path traversal vulnerability in the file write |
| gpt-4.1-mini | Non-integer pagination inputs cause type errors |
| gpt-4.1-mini | Thread-safety risks under concurrent access |
| gpt-4.1-mini | Clock-skew loophole in time-based security checks |
| gemini-3.1-pro | ReDoS from nested quantifier in the regex |
| gemini-3.1-pro | Mutable default argument shared across calls |
| claude-sonnet-4-6 | Timezone offset edge cases (UTC+5 vs UTC-5 produce wrong expiry) |
| claude-sonnet-4-6 | Missing has_prev metadata in pagination response |
| gpt-4.1 | re.match vs re.fullmatch (newlines bypass the pattern) |
| gpt-4.1 | O(N) per-request cost and unbounded memory growth |
Any single model would have caught at most 3-4 of these. Most of the rest would have been invisible.
when to use it
It's most useful when you're making a "should we?" decision and want more than hedged opinions, when you're reviewing high-stakes code like auth flows or payment logic and want to catch the cases where any individual model would be confidently wrong, or when you need a defensible decision and "I ran this through 5 models, they debated for 3 rounds, 4 agreed, 1 dissented on X" is more defensible than "Claude said it's fine."
Skip it for simple factual questions, for generating code (verd reviews, it doesn't write), or for anything where speed matters more than depth. Think of it like a code review from several senior engineers that costs roughly $0.01-$0.40+, depending on the mode: you wouldn't run it on every line, you'd use it on the 3 decisions that actually matter.
try it
pip install verd# Works with any OpenAI-compatible API
export OPENAI_API_KEY=your-key
export OPENAI_BASE_URL=https://openrouter.ai/api/v1
# Security review
verd "can this auth middleware be bypassed?" -f auth.py middleware.py
# Architecture decision
verd "Kafka or RabbitMQ for our event pipeline?" -f architecture.md
# Pre-merge review
verdh "should we merge this?" -gb main
# Pipe anything
cat deploy.yaml | verd "any misconfigs that could expose prod?"Works as a CLI, an MCP server inside Claude Code and Cursor, and a Slack bot.
verd is open source (MIT). GitHub.
Research cited: JudgeBench (Tan et al., ICLR 2025), TrustJudge (Wang et al., ICLR 2025), Sage (Feng et al., ICLR 2026), Judging LLM-as-a-Judge (Zheng et al., NeurIPS 2023), The Silent Judge (Marioriyad et al., 2025), Multi-Agent Debate (ICLR 2025), Analyzing Uncertainty in LLM Judges (Chen et al., EMNLP 2025), Justice or Prejudice (IBM, ICLR 2025).